Morphological Analyzer
Morphological Analyzer
Morphological Analyzer
MORPHOLOGICAL ANALYZER FOR MALAYALAM
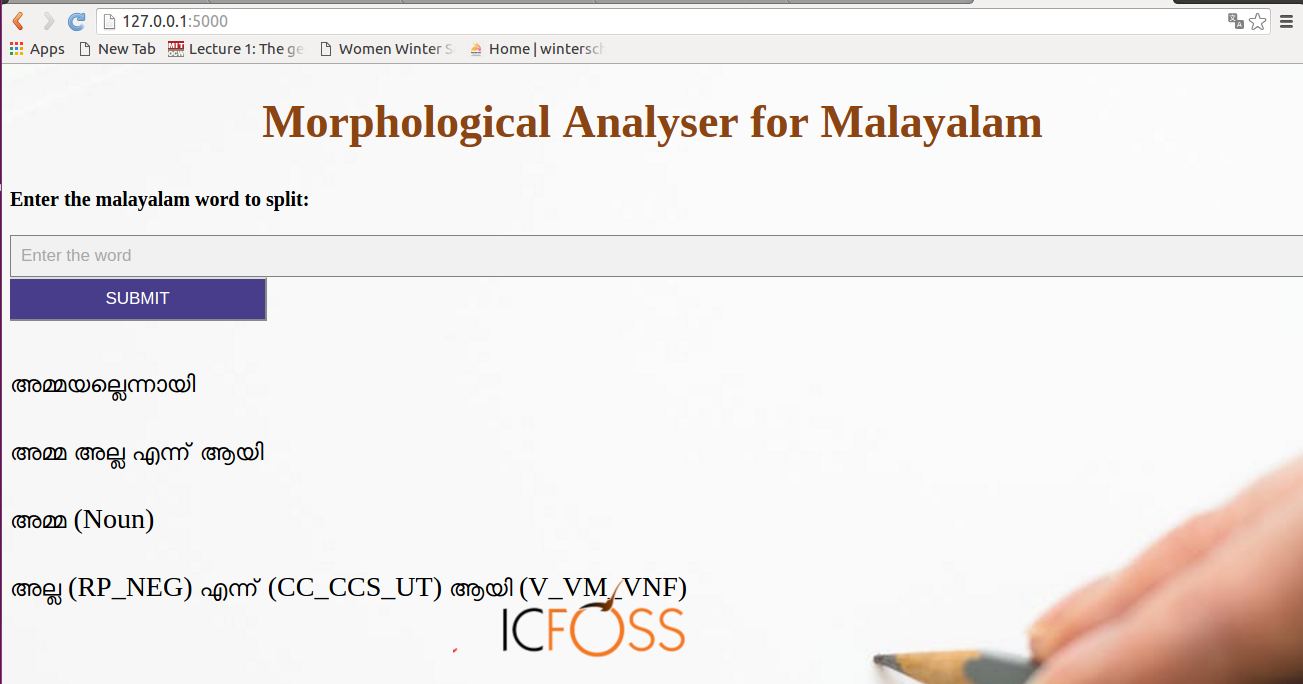
Morphology refers to the identification of a word stem from a full word form. It deals with the study of words and their internal structure. Morphological Analyser is a program for analysing the morphology of an input word, detects morpheme of any text and their analysis. Malayalam is a highly agglutinative language, numerous suffixes can be joined together with the root word to produce a compound word. The challange faced by most of the projects in Malayalam language processing is the task of preprocessing the data. Malayalam language is rich with a wide range of inflections, multiple suffixes etc and this presents a major obstacle in the preproceesing stage and hence there is a vital need for this project as it is mandatory as a supporting tool for almost all the projects.
ICFOSS has developed a web based morphological analyser tool for Malayalam. The proposed system uses recursive suffix stripping methods and moreover, the sandhi rules are also taken into consideration during the stemming process. A rule-dictionary based approach is used, where four modules are incorporated together, in the development of the project. The first three modules ‘stem’, ’split’ and ‘dvithva’ are suffix stripping modules and strips apart suffixes until no suffix is left at the end of the word. Each of the module serves one another while stemming. The system has 4 type of dictionaries, the dictionary with the valid suffixes, one with suffixes whose first letter doubles at the time of joining, the dictionary with the root words and a dictionary of verbs. These three dictionaries are of atmost relevance since the accuracy of the analyser depends on these dictionaries. The final word is looked up in the ‘root word’ dictionary and lastly, the fourth module ‘tag’ assigns tags to the suffixes. The Result produced is the list of Suffixes along with its tags and the root word.
Related Projects
Automate & Simplify The Whole Process

Dependency Parser
A Dependency parser is important for applications like sentence structure identification, machine translation, clause boundary identification,question answering system etc. No work has been done so far in the field of dependency parser for Malayalam using machine learning approaches.
Read more

Dwanimam – POS editor
Dhwanimam – Malayalam POS tag checker is a web based application, developed by the team at ICFOSS, which provides an opportunity to edit Parts-of-Speech (POS) tags assigned to Malayalam words.
Read more


Malayalam ChatBot
ICFOSS developed a Malayalam Chat-Bot, which interacts with the system users, like a human conversational partner in MALAYALAM. A chatbot can be used as a conversational agent which gives information to the public.
Read more

Malayalam Filthy Comment Detecor from Facebook
Social media are interactive computer-mediated technologies that facilitate the creation and sharing of information, ideas, career interests and other forms of expression via virtual communities and networks.
Read more

Malayalam Transliteration Tool
Machine Transliteration is the practice of converting a character or word written in one language to another .Machine transliteration can play an important role in natural language application such as information retrieval and machine translation, especially for handling proper nouns and technical terms, cross language applications, data mining and information retrieval system. This tool is to convert a malayalam name entity to corresponding English word.
Read more
DHRITI – Malayalm OCR
The project aims at creating an efficient searching and information extraction system that can process a large set of Malayalam documents and produce the most accurate results based on a user query
Read more

Plagiarism Checker
The widespread use of the Internet has made the plagiarism of documents very easy. So plagiarism detection is one of the main concern in the field of academia and research.
Read more
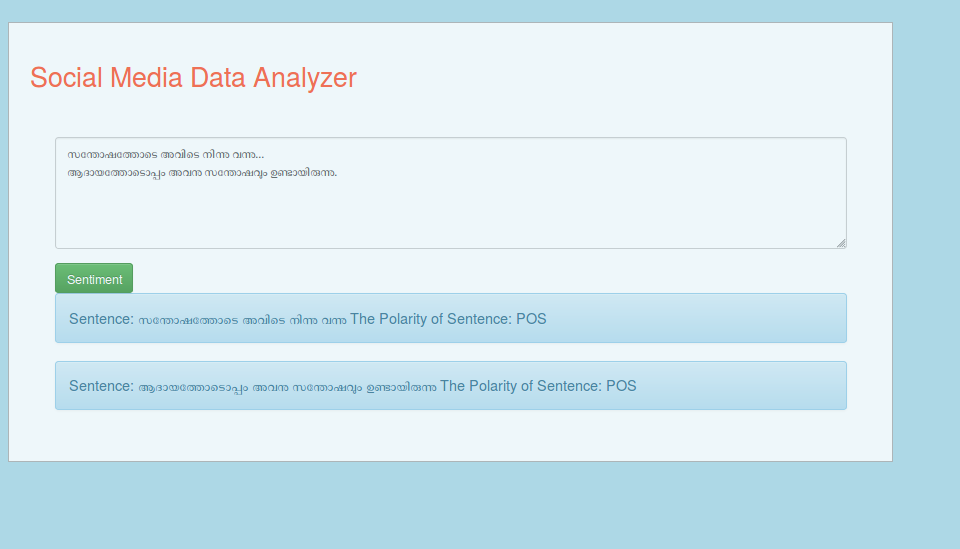
Social Media Analytics
The presence of social media has made a tremendous changes in the way how people see the world outside.
Read more
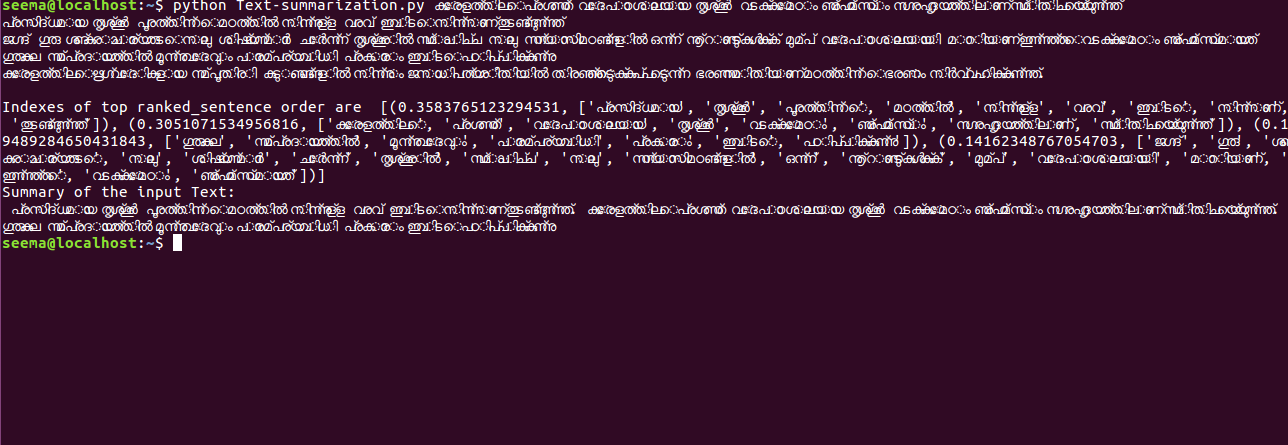
Malayalam Text Summarisation
There are two main types of how to summarise text in NLP (1) Extraction-based summarisation and (2) Abstraction-based summarisation.
Read more